Google Cloud Platform AutoML Vision -AI画像解析でイメージカラーを抽出する-
昨今は多種なAIサービスがリリースされています。AIに関連して機械学習、深層学習(ディープラーニング)という言葉も良く耳にします。AIはArtificial Intelligenceの略で、「人工知能」と同義で、人間の脳が行っている作業を人工的に再現するためのソフトウェアやシステムです。そのなかで、機械学習と深層学習はAIを構成する要素のひとつとなります。その他にシミュレーション、ビッグデータ分析技術の計算システムもAIに含まれます。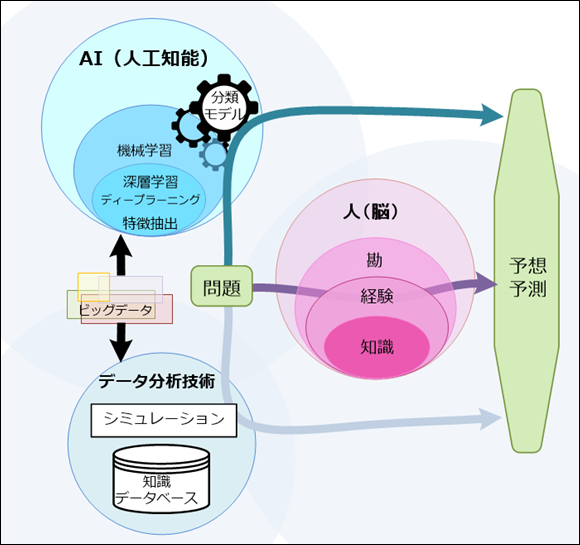
機械学習 (Machine Learning:略称ML)
機械学習は経験から学習で反復学習し、学習結果を使って自動で特定のタスクを機械「コンピューター」に実行させるものです。ここでいうタスクとは、コンピューターが解くべき課題を示します。今回の課題の例として「画像からイメージカラーを抽出する」というのを上げています。これがタスクにあたります。
データセット
経験は何らかのデータとしてコンピューターにインプットします。このデータを学習データ(あるいは訓練データ)といいます。上述のタスクであれば画像とその画像に対するイメージ色が学習データとなります。このデータの集合体をデータセットと呼びます。データセットを用いてコンピューターの分析性能を改善する過程をトレーニング(訓練)といいます。
深層学習 (Deep Learning:略称DL)
多数の層から成るニューラルネットワーク(脳神経回路の一部を模した数理モデル)を用いて行う機械学習のことをいいます。これにより、コンピューターがパターンやルールを発見する上で何に着目するか(特徴量という)を自ら抽出することが可能となり、人による特徴定義が不要となります。反面、判定結果を説明できない。判定過程がブラックボックス化される弊害もあります。
シミュレーション
何らかのシステムの挙動を、それとほぼ同じ法則に支配される他のシステムや計算によって模擬すること。(Wikipedia)
解析すべきデータは人によって直観的に理解できる説明変数(パラメータ)で構成される分析モデルが多くなります。
「画像からイメージカラーを抽出せよ」という課題であれば、色の面積、色の配置、色の好み(リサーチによる収集)をパラメータ化すれば良いのではというのが思いつきます。
課題「画像からイメージカラーを抽出する」
画像からイメージカラーを抽出したい場合、計算だけのシミュレーションによる場合と機械学習によるAI画像解析で導き出す方法が全く違います。シミュレーションと機械学習による最初のアプローチは、シミュレーションであればアルゴリズムの作成、機械学習であれば訓練データの作成となります。
シミュレーションによるイメージカラーの抽出方法
下記のホームページ画像のイメージカラーはなんでしょうか?大抵の人は赤、赤紫と答えます。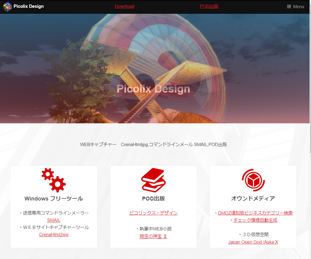
計算によるシミュレーションではまずアルゴリズムを考えます。
イメージカラーの算出アルゴリズム (一例)
1.画像をぼかす
2.画像を縮小する(縦横50ピクセル)
3.画像を16色に減色する(総数2,500ピクセル)
4.各色の総ピクセル数をカウントする
5.明度、彩度、重み付け(人の色に対する感度)により各色のスコア算出する
6.スコア順で連続する同一色を間引きする
7.スコアからトップ3のRGBを決定する
8.RGBを色データ表から一番近い色名を最小二乗法で算出する。※色データは16色名、モノクロ、和名英名混在の3種類用意しています。65,536色のすべての色名データがあればこの計算は必要ありません。
大雑把ですが上記のようなアルゴリズムになります。筆者の作成したイメージカラー分析プログラムはこちらのGitHubにおいておきましたので興味あるかたは参照してください。
よりアカデミックに知りたいかたはこちらの文献が有用です。(20年以上前の古い文献になります)
・「テキスタイルデザイン画像におけるイメージ・カラーの選定法」-情報処理学会論文誌- 1995
・「配色の反映を利用したデザイン支援ツールの構築」-情報処理学会火の国情報シンポジウム2003論文集
イメージカラー分析プログラムの実行例を記載しておきます。
この画像のイメージカラーは[紫]、[赤紫]、[青]、色名では[ボルドー]、[ラベンダー]、[紺青(こんじょう)]という結果です。
このようにプログラムの計算で答えを得ることができます。(結果の正確性はここでは問いません)
パラメータは各色の重み付け(人の色に対する感度)だけですが、これに色の配置、他色との相互関係などをルール化、数値化すればより正確な答えとなります。
AutoML Vision 機械学習によるイメージカラーの抽出方法
機械学習での最初のアプローチはなんでしょうか?
まずよく間違えるのがビッグデータがあるのでこのデータから何か有用な結果を導き出そうというプロセスは間違いです。
先に課題があって、その課題を解決するためにどういうデータが必要なのかを考える必要があります。
「画像からイメージカラーを抽出」という課題は複雑ではないですが漠然としています。
データは画像でその画像に対してイメージカラーである色名1、2のデータセットを用意できればよさそうです。
データセットさえ用意できればGoogle Cloud Platform AutoML Visionで機械学習、画像分類モデルの構築がノンプログラミングで行えます。
画像はホームページのスクリーンショットとし、スクリーンショット約3万枚と色名は筆者の管理サイト
https://search.picolix.jp/dmoz/index.php?s_keyword_in=ITのデータを利用しました。
データセットをAutoML Visionに登録した結果が以下です。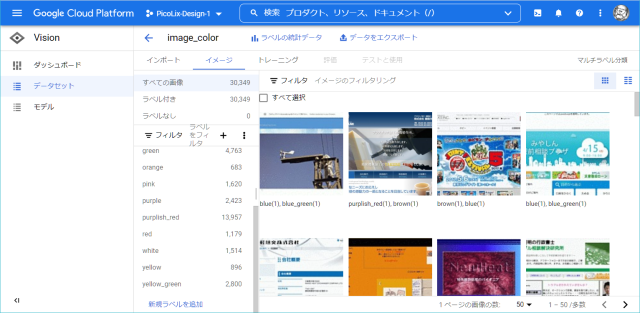
今回検証したGoogle Cloud Platform AutoML Visionの詳細な設定手順はこちらです。
学習結果は次のようになりました。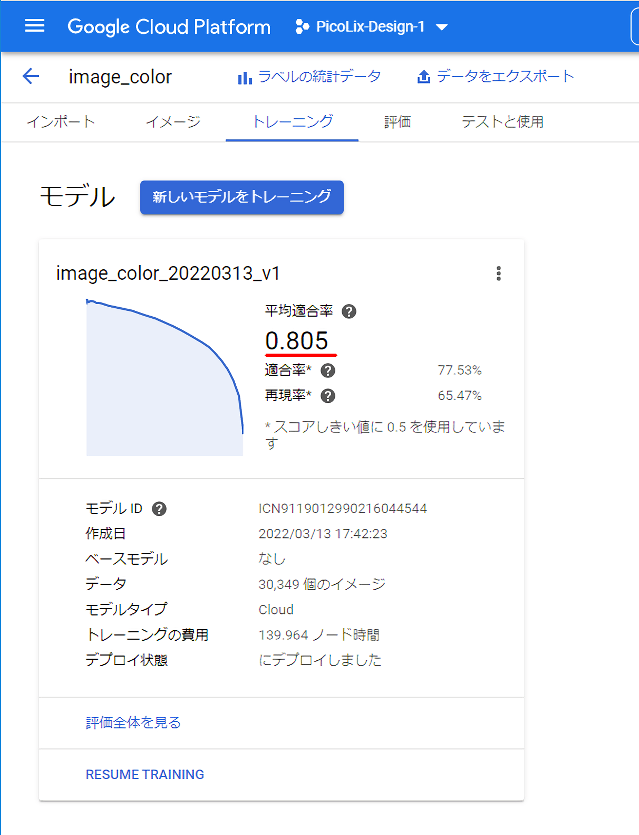
平均適合率は、1.0に近いほどより良いデータモデルです。適合率と再現率は100%に近いほど正確です。結果は平均適合率0.805 適合率77.53% 再現率65.47%となりました。
平均適合率は80.5%で90%を越えませんでしたがまずまずです。適合率は抽出した2色がどれだけ判断が正解だったかの割合で77.53%で良いでしょう。再現率は実際抽出した2色のデータの内どれだけ判断が正解だったかの割合で65.47%です。
もっと厳しい予想をしていたのですが評価できると思います。適合率と再現率はトレードオフの関係でどちらを優先するかはAutoMLでは設定できません。適合率と再現率の両方を向上させたい場合はより多くのデータをラベル付けすることになります。
この学習モデルをつかって最初に記載したホームページのイメージカラーを判定した結果以下です。
イメージカラーはbown[茶]-purplish_red[赤紫]という結果が出ました。
※AutoML Visionの仕様上ラベル名に日本語は使えません。色は英単語で登録しています。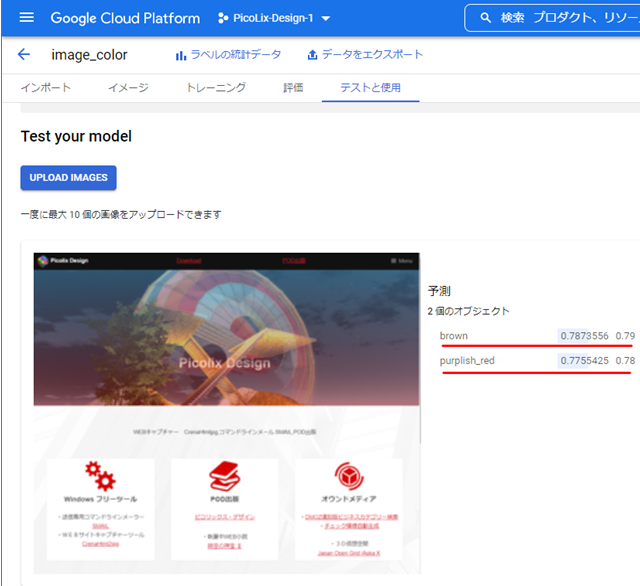
brown(茶)が第一候補に出てきますが、これはもともとの16色データの精度が良くないためと思われます。それなりの答えが出ていますので良しとしましょう。画像とラベルをAutoMLに喰わせることで、アルゴリズムやプログラムを全く気にすることなく、学習モデルを作ることができます。
データセットだけで学習モデルを作成してイメージカラーを抽出できました。
| 方法 | イメージカラー抽出結果 |
| 人の感性 | [赤]‐[赤紫] |
| 抽出プログラム | [紫]‐[赤紫] |
| AI画像分析 | [茶]-[赤紫] |
画像データとラベルデータをAutoML Visionに投入するだけでノンプログラムミングで、ルールや特徴量などを全く気にすることなく実装できます。
皆さんも今後、機械学習を実装する場面がありましたらAutoML Visionを候補として検討してみてください。
注意事項:
3万画像、1画像2ラベル、ラベル種類16種の学習モデル生成に18.5時間、140ノード時間を費やしました。1ノード時間あたり$3.465の費用が発生します。
Google Cloud Platformの無料クレジット$300、AutoML Visionの初回利用の学習モデルトレーニングの無料クレジット約$126、合計$426を1回の学習モデルトレーニングで一気に使いきりさらに6,000円ほどの課金が発生しています。
世間でいうクラウド破産の扉を垣間見た気分です。
画像枚数が1,000枚ぐらいで小規模な実験であれば、この$426で十分複数回検証可能です。また学習モデルトレーニング設定時に使用ノード時間の予算設定もできますので慎重に行ってください。
番外編:錯視画像は見分けられるか
【錯視その1 イチゴの色】
「北岡明佳の錯視ページ」色の錯視 16 より
この画像には赤系統のピクセルは全く含まれていません。しかしながら、イチゴが赤く見えます。色の恒常性による一種の錯覚です。この画像はイチゴは赤いという思い込みで見えているのではありません。各ピクセルの配色とその位置関係でこのような錯視が起こります。
この画像をイメージカラー分析プログラムにかけると、イメージカラーは「青緑」です。イメージカラーの抽出は、元のピクセル色から画像編集して色味の係数から算出していますが、赤系統の色数がゼロであり、人間のように赤系統に判定がでる要素が全くありません。
機械学習で覚えさせた分類モデルでもこの種の情報は入れていないので、赤とは答えられません。錯視のデータを学習させる必要がありますが多様な錯視のデータを集めることが可能なのか疑問です。機械学習以外の別のアプローチが必要かもしれません。
【錯視その2 ドレスの色】
次の画像はドレスです。
https://en.wikipedia.org/wiki/The_dressより
このドレスは「白と金」でしょうか?「青と黒」でしょうか? 人によって答えは違います。
https://style.nikkei.com/article/DGXMZO85079060R30C15A3000000/
筆者には「白(ブルー系)と金」に見えますが、妻と娘は、「青と黒」にしか見えないと言っています。
この画像もイメージカラー分析プログラムにかけてみましょう。
この結果からすると、「白(青系)と金(クリームイエロー)」が正しそうです。人により全く違う色に見えることを機械学習から予想させるにはどのようなデータが必要でしょうか?これもまた自動判定するには別のアプローチが必要かもしれません。
最後に
いかがでしたでしょうか。プログラミングで計算する方法とは違い、機械学習においてはどのようなデータセットを集められるかによりその真価が発揮されます。
ドメイン・サーバー同時契約でドメイン更新費用永久無料(年間最大3,858円お得)
是非、お得なこの機会にご利用ください。最新のキャンペーンはこちらから

※ユーザーノートの記事は、弊社サービスをご利用のお客様に執筆いただいております。
医療メーカーで新素材研究開発後、電機メーカーで制御器系システム開発を経てIT系マルチエンジニアをしています。またデザイン思考を実践し、アート思考などのいろんな思考方法に興味があります。







 目次へ
目次へ